一文搞懂DDD核心概念
这是我通过自己的理解整理的DDD核心概念,如果存在翻译不准确,或解释不清晰的问题,欢迎指正。
基本概念
统一语言 Ubiquitous Language
软件开发过程中,业务专家(领域专家)和技术团队使用一致的术语来描述业务规则、流程和模型,避免歧义和沟通障碍。
限界上下文 Bounded Context
限界上下文是DDD中用来划分业务领域的边界,每个上下文代表一个独立的业务语义环境,内部有自己的一套术语、规则和模型。
限界上下文之间有明确的业务边界、协作边界。
上下文映射 Context Map
描述了不同的上下文之间如何集成,上下文映射有几种常见的模式:合作关系(partnership)、共享内核(Shared Kernel)、开放主机服务(Open Host Service)、发布/订阅(Publish/Subscribe)等
贫血模型 Anemic Domain Model
对象只有数据(属性)和简单的getter/setter,是纯数据对象,没有业务逻辑。
充血模型 Rich Domain Model
也叫富领域模型,对象不仅有数据,还理解业务规则。
充血模型与面向对象编程的理念是一致的,因此常放一起说;而贫血模型则是对应的面向过程编程
几位DDD领域的专家
- Eric Evans,2003年出版《Domain Driven Design》一书,首次提出DDD的概念
- Vaughn Vernon,曾出版《Implementing DDD》,对DDD的发展产生深远影响
- Robert C. Martin(Uncle Bob),提出Clean Architecture,现在DDD的实践落地很多都参考了这种架构模式
架构模式
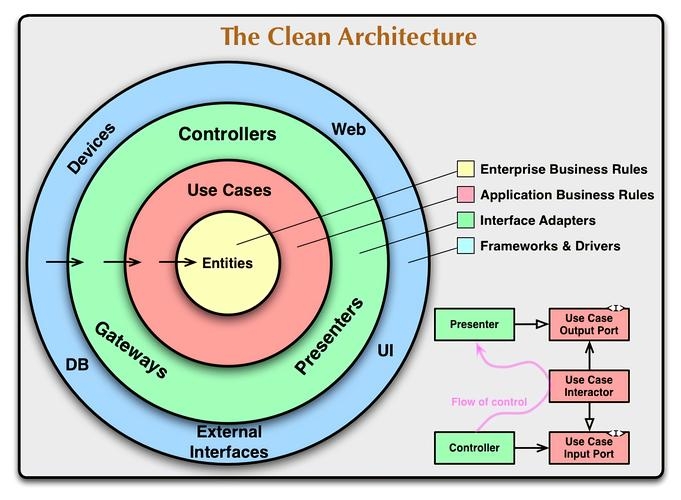
整洁架构 Clean Architecture
一种架构模式,由Uncle Bob提出,整洁架构的特点是:
- 独立于特定的技术框架
- 易于测试
- 独立于UI
- 与具体的数据库无关
- 与任何外部代理无关
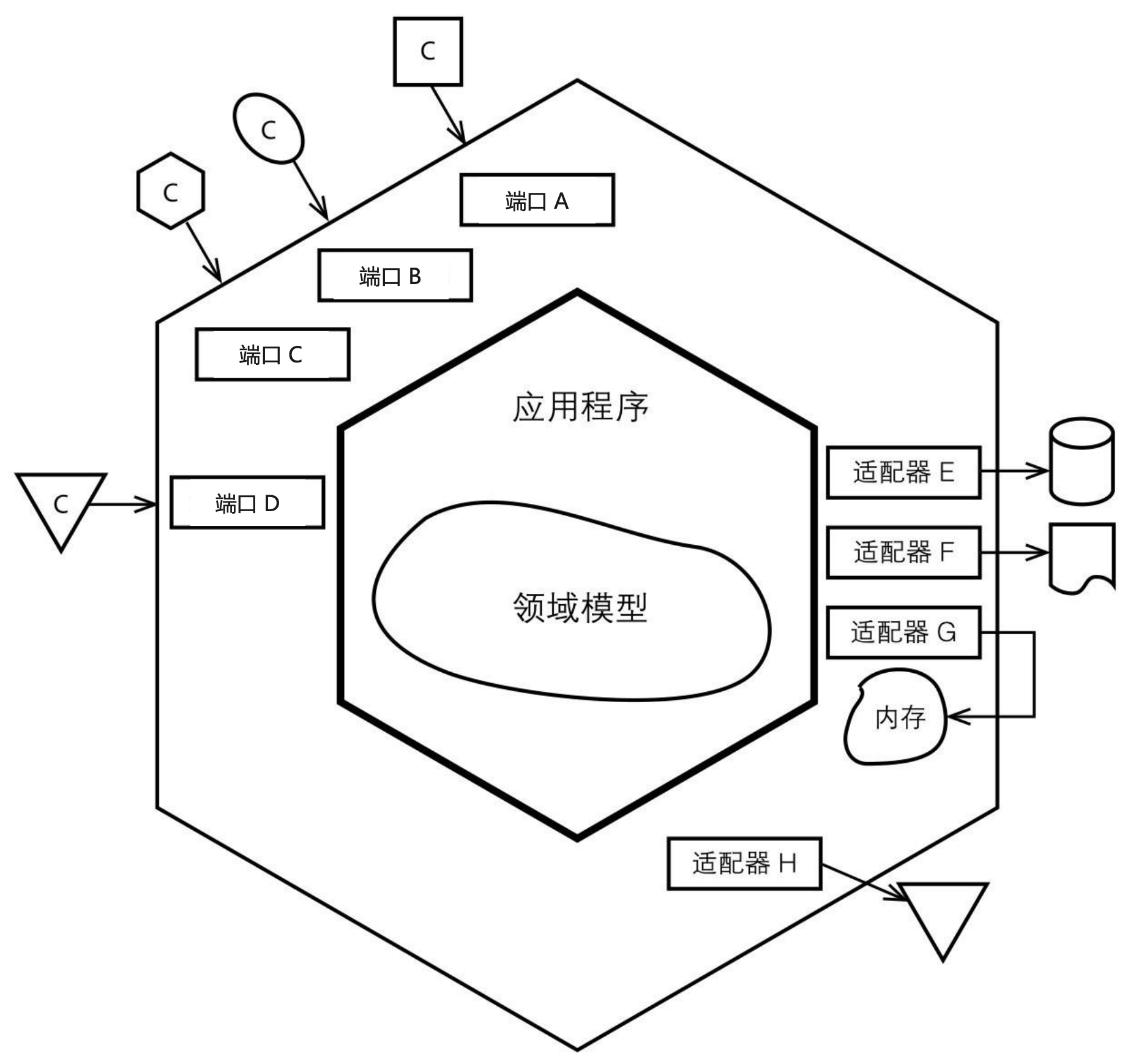
六边形架构 Hexagonal Architecture
也是一种架构模式,由Alistair Cockburn提出,其思想内核与Clean Architecture有类似之处,并提出了端口-适配器模式
CQRS
CQRS(Command Query Responsibility Segregation)是一种架构模式,核心思想是将系统的“写操作”(Command)和“读操作”(Query)分离,使用不同的模型来处理,以提高性能、可扩展性和代码清晰度。
但CQRS其实并不等同于“读写分离”,正常如果你要做读写分离,在数据访问层做就好了,加一个备库和主从同步,写请求在主库,读请求转发到备库上。这叫读写分离,但不叫CQRS。
CQRS可以理解为在业务上划分了读和写,二者在业务复杂性上属于不同的维度,“写”往往是比较内聚的,很适合套用DDD的建模思想,“读”的复杂度体现在条件多样化、还要做信息聚合(可以想象一下电商平台的聚合查询页面)
不过在业务上划分了读和写,并不意味着一定要分成“读应用”和“写应用”,这是把CQRS极端化了,这一点可以参考沈剑老师的一篇文章,与我的思想不谋而合:《别扯什么CQRS,服务做什么读写分离,就离谱!》
架构分层
Application Layer
应用层,或应用服务层。限界上下文通过应用服务层对外提供业务能力,同时应用服务层又对内部的领域层进行组合和编排。
Domain Layer
是DDD最核心的一层,包含了最核心的原子业务模型。领域层不对任何其他层产生依赖,是纯粹的“业务”。这样做的好处是进行业务建模时可以不受某个特定技术的影响,更易于进行业务建模和测试。
Infrastructure Layer
是整个限界上下文的“技术边界”,基础设施层直接与网络、硬件、外部渠道、数据库等交互,把应用层“包裹”在内。
基础设施层在调用方向上可以分为外部访问内部、内部访问外部,分别对应入口网关和出口网关。
入口网关 Inbound Gateway
限界上下文对外提供的访问端口,可以对应到六边形架构中的Port,从形式上包括HTTP(S)、RPC、MQ、命令行触发等。入口网关需要把各种技术协议转换为应用层的业务服务,是从外到内的桥接层
出口网关 Outbound Gateway
与出口网关相对,是限界上下文访问外部的桥接层,是对外部服务、数据库等的封装和实现。出口网关对应着六边形架构中的Adapter的具体实现。
Anti-Corruption Layer
防腐层,严格意义上说并不是真实存在的一个物理层。因为基础设施层与外部直接交互,需要感知到外部的技术细节,但核心业务层是稳定的,不希望感知太多外部细节。那么这一矛盾就需要由防腐层来解决。
例如要发送短信,就需要对接不同的短信运营商,不同的运营商接口就不一样,在出口网关必须要感知这个不同。但是在应用层,我们希望能统一使用一个高度抽象的MessageSender接口,这个MessageSender就是防腐层。不同的短信运营商可以有不同的MessageSender实现。
相关信息
关于防腐层,在我的另一篇文章中有提及,可参考:三句话说清DDD的思想内核
领域层
实体 Entity
是充血的数据对象,包含了数据和业务规则,且数据和业务规则是内聚的。每个实体都有一个唯一标识(ID),例如订单、用户、账户等。
值对象 Value Object
也是充血的数据对象,也可以包含业务规则,但没有唯一标识,例如Money、Address、Phone等。
Domain Primitive
我个人认为Value Object和Domain Primitive是等同的。
但如果硬要抠字眼的话,值对象更多体现的是Immutable(不可变)特性,而DP是升级版的值对象,除了不可变以外,还提供了一些方法。
例如Money可以提供加减乘除运算,当然由于不可变性,计算完后会生成一个新的Money对象。
聚合 Aggregate
一组紧密关联的领域对象的组合,作为数据修改的最小单元。例如订单(Order)和订单项(OrderItem)应该是要同时访问和修改的,单独对订单项进行修改会破坏封装性,也没有意义。
二者形成了一个聚合,以一对多的形式存在,看成一个整体。
聚合根 Aggregate Root
在一个聚合里面,一定有一个根对象,称之为聚合根。通过聚合根来访问整个聚合的内部信息。
领域服务 Domain Service
对不同聚合的封装,聚合是严格面向对象的和内聚的,但聚合之间也要有交互,例如充值成功,需要把充值单置为成功,还要增加账户余额。
充值单和账户这两个聚合可以完成各自的逻辑,但是要把这两者放到一个事务内,就需要用到领域服务。
相关信息
可以理解为领域服务是面向过程的,关于应用服务和领域服务,都是在做组合和编排,二者的区别可以看这一篇:《DDD应用服务、领域服务傻傻分不清楚?看这篇就够了》
领域事件 Domain Event
表示领域中已发生的重要事件,用于解耦系统组件或触发后续动作。把所有领域事件串联起来还可以形成Event Sourcing(这又是另一种架构模式,后续有空再介绍)
资源仓库 Repository
Repository是对数据访问的抽象,可以理解为是对数据访问特有的防腐层,通过Repository我们的核心领域层就可以不需要关注特定的数据库实现细节。
提示
一般Repository和Aggregate Root是一对一关系
工厂 Factory
封装复杂聚合或对象的创建逻辑,其实对象的创建过程是比较复杂的,包含一些数据转换、参数校验、数据有效性检查等,可以把这些逻辑都封装在工厂里。
提示
这里所说的工厂与设计模式中的简单工厂基本是一致的