Redis 主从复制
简介
主从复制主要用于防止单点故障,一个master节点和多个slave节点组成主从复制集群,当master下线后,其中一个slave可以升级为master以保证服务可用。
整体架构如下: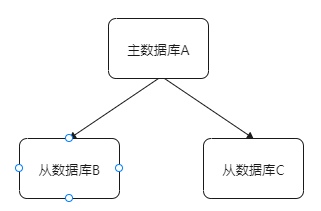
使用slaveof <master ip> <master port>命令可以把一个redis设置为对应master的从库,默认情况下从库是只读的,通过修改配置项slave-read-only来改变只读状态,但一般还是建议从库只读。
复制原理
- Redis从库连上主库后,会发送
SYNC命令开始同步数据 - 主库收到
SYNC命令,开始保存快照(RDB持久化),并将保存快照期间接收到的命令进行缓存 - 快照完成后,将快照文件和所有缓存的命令发送给从库
- 从库载入快照文件,然后执行缓存的命令
以上过程称为复制初始化,当复制初始化结束后,主库收到写命令就会将命令同步给从库以保证主从数据一致。
但复制初始化比较耗时,即便是从库短时间内断开重连,也需要同步完整的主库数据
注意
在复制初始化过程中从库不会阻塞,可以继续处理客户端发来的命令,并使用同步前的数据进行响应。这里可能会存在数据不一致,可以修改配置项slave-serve-stale-data为no,这样在同步期间收到的查询命令都会返回 SYNC with master in progress。
这里需要在可用性和一致性之间做一个平衡
无硬盘复制 2.8.18
上面说到复制过程需要用到RDB持久化,包括从库也是使用RDB快照恢复的方式恢复数据。即便主库禁用了RDB快照,在进行复制初始化时依然会生成快照,这是为了复用已有的功能,但缺点也很明显。
- 快照发生的时间不可确定,恢复数据的时间点也会不确定
- 在复制初始化时需要写磁盘,当redis作为缓存使用时可能会产生性能上的影响
可通过配置repl-diskless-sync yes开启无硬盘复制,在复制时不会把快照存储到磁盘上,而是直接通过网络发送。
增量复制 2.8
上面提到基于SYNC的同步采用的是全量复制,在2.8版本后支持了PSYNC命令的增量复制方式。实现原理如下:
- 从库会存储主库的运行ID(run id),运行ID是唯一的,且重启实例后会重新生成
- 在复制过程中,主库会维护一个积压队列 backlog,用于保存同步到从库的命令以及偏移量
- 从库接收到主库传来的命令时会记录命令的偏移量
- 主从连接建立后,从库发送
psync <master run id> <最新偏移量>给主库 - 主库收到同步命令,判断run id是否相同
- 判断从库发来的最新偏移量是否在积压队列中,如果存在则进行增量复制,否则进行全量同步
提示
积压队列是一个固定长度的循环队列(类似mysql的redo log),默认情况下大小为1M,可通过配置项repl-backlog-size来调整。
另一个配置项repl-backlog-ttl指当所有从库都与主库断开连接后,需要多久释放积压队列的内存,默认1小时。
高可用
在主从模式下,通过Sentinal来实现高可用