Dubbo线程池占满问题定位
原创2021/1/22大约 4 分钟
问题现象
生产系统日志告警,dubbo线程池被占满,请求阻塞。
排查思路和步骤
遇到问题不要慌,先dump后重启,通常能解决一大半问题,然后顺着下面的思路逐一排查:
- 排查除了线程池占满以外,是否还有其他错误日志,或许存在相关性
- 考虑是否存在流量突增,请求无法及时响应
- 考虑是否存在性能问题,最可能的是调用下游系统的接口性能突然下降,或者MySQL存在慢查询
- 考虑是否存在内存溢出或内存泄露,由于频繁GC导致的性能下降
- 考虑并发问题,由于锁竞争导致接口性能下降
排查步骤:
- 查看了环境日志,除了线程池相关的错误,未发现其他错误日志
- 通过服务流量监控,未发现明显的流量增长,通过top命令也未发现CPU飙高,可以排除流量突增的问题
- 通过服务监控系统查询下游系统的接口耗时,未发现下游接口超时的情况(若没有服务监控系统,至少应在本地打印下游接口超时的相关日志,根据日志也可排查问题)
- 慢sql系统检测到部分sql耗时较大(1000 ~ 3000ms)左右,但分析这些sql与dubbo线程的问题无关,这一点作为疑似项待定,继续往下排查
- 查询gc日志,发现gc比较频繁,基本可以断定存在内存溢出或内存泄露
- 通过
jmap -dump导出堆快照,使用MAT工具进行分析,分析结果如下
通过Dominator Tree分析发现DruidDataSource对象占用了61%的已用内存: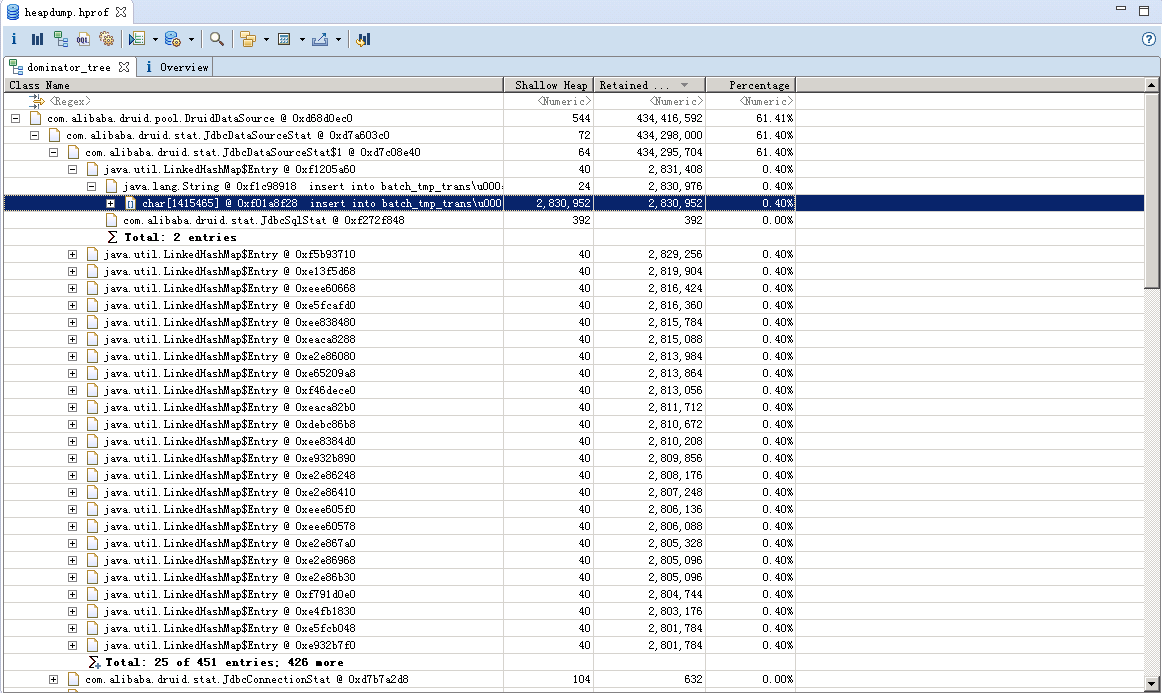
druid中有一个sql统计功能(设置druid.filters=stat),用于对sql的执行效率进行统计,统计结果保存在HashMap中,map的key就是sql语句,value是统计信息。关键在于当时执行了批量解析入库的操作,每1000条数据批量入库一次,最长的sql语句达到了2.7M长度,大量这些长sql驻留在map中导致了内存溢出。这个map中最多缓存1000个sql统计信息(通过druid.stat.sql.MaxSize可以调整),在单条语句过长的情况下,1000条sql足以撑爆内存。
- 还可以通过
jstack -l导出线程堆栈来分析是否存在并发资源竞争,但由于问题已经定位出来,实际并没有排查到这一步。这里仅做理论分析:如果当时正在进行young GC或CMS的initial mark或remark阶段,存在STW,业务线程会全部阻塞;如果处在CMS的concurrent mark或concurrent sweep阶段,部分线程被GC占用也会阻塞。但线程堆栈更多用于排查线程同步或死锁问题,在这个案例中帮助不大。
现在回头看步骤4的慢sql,果然就是那些批量入库操作,也就是这些sql间接导致的问题。
问题解决
- 调小
druid.stat.sql.MaxSize参数,或直接关闭druid的sql统计功能 - 调大堆内存:-Xms2048m -Xmx2048m -Xmn1280m
- 关于批量insert的问题在性能上是否有优化空间?留一个问题待后续专门讨论
总结
- druid数据源的SQL统计功能弊大于利,一般情况下都可以关闭。SQL统计可通过MySQL自带的功能,或相关sql统计工具来查询,没必要集成到应用内
- 在微服务架构下,服务监控和治理功能尤为重要,包括但不限于
- 单个服务的监控,包括服务的流量和性能监控
- 全链路监控,通过服务链路理清调用关系,快速排查影响范围
- 熔断、限流、降级功能,在微服务架构下,任何一个节点的故障可能都会影响到整个链路,这时候若具备这些能力,可以降低对全局的影响。
- 生产环境应具备快速查询问题的能力(例如查看日志和JVM运行情况),现在的生产集群动辄部署上千台机器,一般开发人员还不具备应用发布账号的权限,如果排查问题需要联系运维或者需要临时申请权限则会耗费较多时间
- 一定要开启GC日志,对排查JVM问题很有帮助